Phase 1 of Eyes on the Glass (EOTG) just started: TORA is triaging synthetic alerts and escalating to VERA. VERA is investigating on these cases and using a synthetic augmented context. Cases are being documented. Before I get into what TORA is finding, I want to explain three design decisions that shape the first phase of this experiment because they’re not obvious, and to me, they matter more than the technology.
Why context is the variable that determines everything
Context in SOCs is fragile, and autonomous systems don’t make that better automatically. I believe you have to architect for it explicitly at every layer. I also learned about how context rot degrades performance of LLMs.
Having separate agents triaging alerts, escalating cases and doing specialized tasks is structured. In EOTG, each agent owns a distinct context window and a distinct task. The autonomous SOC works because of the curated context passed between them. TORA doesn’t need to know how to do root cause analysis. VERA doesn’t need to see every alert TORA closed. NOVA doesn’t need case-level detail. Each agent gets exactly what it needs to reason well, nothing more.
This is why the input schema is designed the way it is. Every alert TORA receives includes not just the raw event, but asset criticality, environment classification, identity context, threat intelligence depth, historical pattern, and suppression history. These are not nice-to-haves. They are the inputs that separate a triage decision from a guess.

Asset criticality alone changes the disposition on the same alert. A DNS query to a malicious domain from a low-criticality development workstation is a different situation than the same query from a server with a trust relationship to your domain controller. The network event is identical. The risk is categorically different. Without asset context, TORA cannot reason about that difference, and an agent that cannot reason about that difference should not be making autonomous triage decisions.
The INSUFFICIENT_CONTEXT disposition exists because of this. When a blocking field is missing, TORA does not guess. TORA names the field, documents what enrichment is needed, and flags the case for retry. I don’t consider this a failure state, I’m using this as evidence that the data pipeline has a gap. An agent that closes alerts when context is missing is not a triage agent. It is a queue drainer.
Why auditability and traceability are core to the design
Every TORA output includes a full reasoning trace: four explicit steps documenting how TORA classified severity, what was ruled out in the false positive assessment, whether context was sufficient, and how the final disposition was reached. This is not optional. It is the most important part of the output.
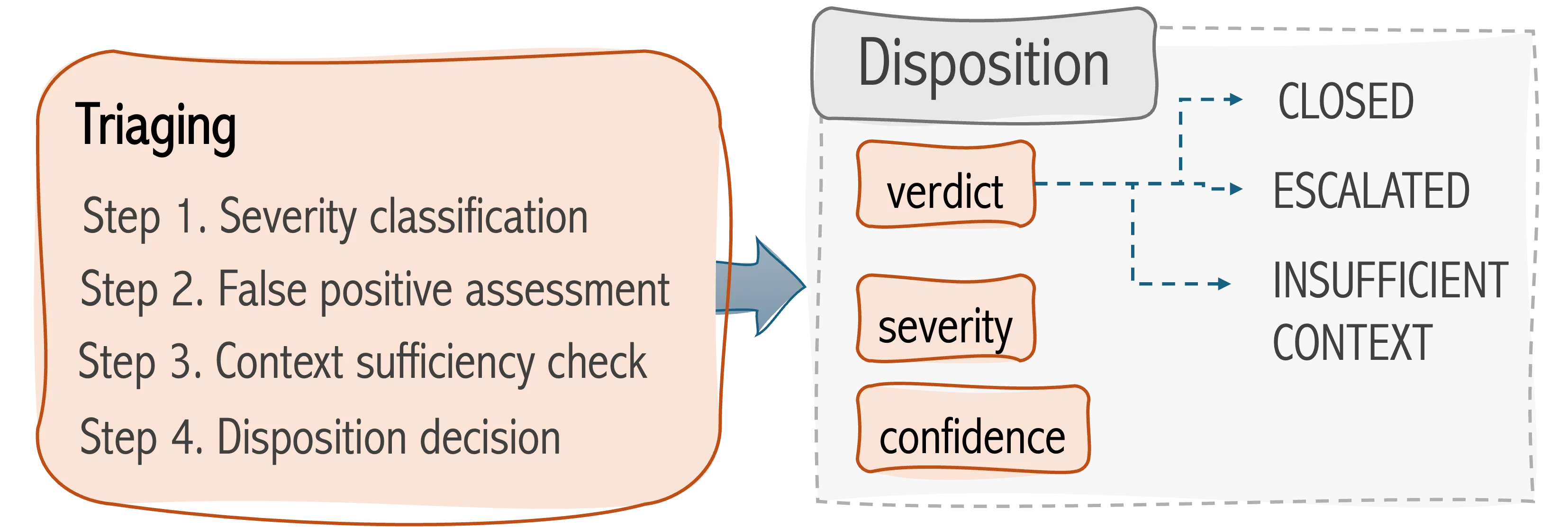
The reason is simple: I need to be able to review TORA’s work and know whether she got it right and why. Not just whether the disposition was correct, but whether the reasoning was sound. A correct disposition for the wrong reasons is a calibration problem waiting to surface as a miss. A wrong disposition with clearly documented reasoning tells me exactly what needs to be fixed.
This matters even more because NOVA is going to be watching. NOVA’s job is for cross-case pattern analysis: NOVA will be observing what TORA and VERA do across all cases over time and surfacing patterns that no single case review would reveal. False positive rates by detection rule. Escalation patterns by asset type. Missing field frequency by pipeline source. The reasoning trace and the nova_feed block in every TORA output are NOVA’s data. If TORA’s reasoning is opaque, NOVA cannot learn from it. If TORA’s outputs are inconsistent, NOVA cannot track calibration over time.
Auditability is also the baseline requirement for trusting the system enough to expand it. I am not going to connect TORA to live production telemetry and let TORA make autonomous decisions without a clear record of how TORA reasons. The reasoning trace is what earns that trust, case by case.
Traceability across the escalation chain is the second half of this. When TORA escalates a case to VERA, the case ID persists. VERA’s investigation links back to TORA’s triage. NOVA’s observations reference both. A single security event is traceable from the raw alert through triage, through investigation, through research observation with a documented record at every step. That is the infrastructure that makes post-incident review meaningful and makes the system improvable over time. Without it, I have outputs. With it, I have a record.
Why Phase 1 starts with synthetic inputs
The answer is: because I do not yet know what TORA gets wrong, and I need to find out in a controlled environment before I find out in a live one.
Synthetic inputs let me design the scenarios. I can construct an alert that should force escalation and verify that TORA escalates. I can construct an alert with a stale IOC and low source count on a development host with a valid suppression match and verify that TORA closes it with the right rationale. I can construct an alert with missing asset criticality and verify that TORA names the blocking field correctly and does not guess.
These are not cherry-picked scenarios designed to make TORA look good. They are the cases that reveal whether the triage logic is correctly implemented. These are the edge cases, the ambiguous signals, the alerts where analysts might disagree. I am specifically generating cases where the decision is not obvious, because those are the cases that matter.
The alternative? connecting TORA to live telemetry in Phase 1 would tell me whether TORA produces output. It would not tell me whether the output is correct, because I would not have ground truth. With synthetic inputs, I know what the right answer is before I see what TORA says. That gap between what TORA should do and what TORA does is the research data.
There is also a practical reason. Live telemetry introduces noise, incomplete data, and edge cases I have not designed for. Before TORA encounters those, I want to understand her behavior on inputs where I control the variables. Phase 2 introduces simulated telemetry from multiple sources. Phase 3 introduces honeypots and real-world attack data. The sequence is intentional: each phase expands the complexity of the environment after the previous phase has established a baseline of how the agents reason. Phase 1 is not a demo. It is the calibration run.
— Jeny Teheran, Security Architect Eyes on the Glass, March 28, 2026